LLM Evaluation for Reproducible AI Reporting
Benchmarking LLM-generated AI method annotations against expert human-curated annotations to evaluate reproducibility and reporting quality in life science AI publications.
Overview
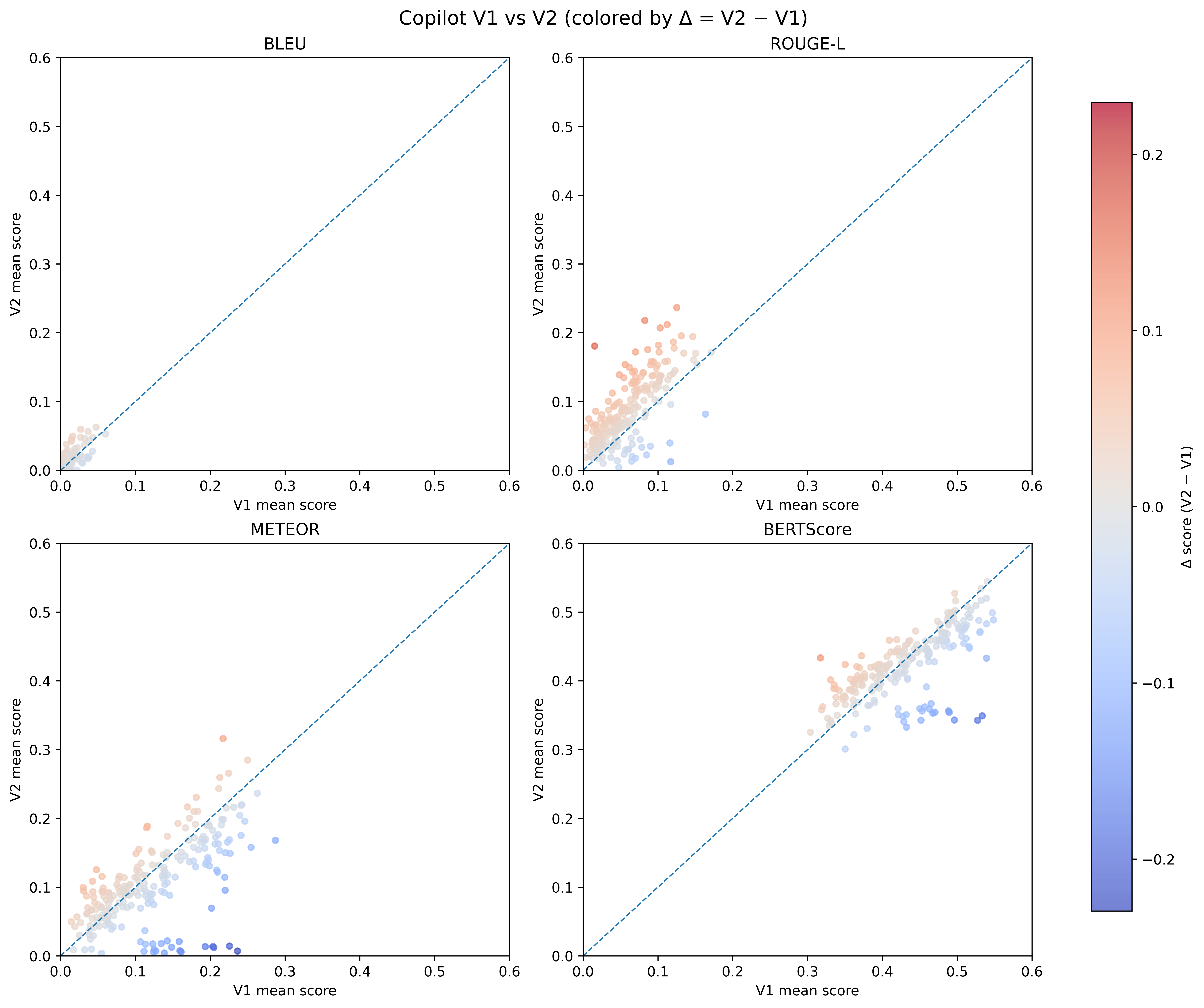
DOME Copilot is a large language model (LLM)-based system designed to automatically generate structured AI method reports from scientific manuscripts following the DOME recommendations for machine learning reporting in biology.
My work focused on the evaluation and benchmarking of LLM-generated outputs against expert human annotations in order to assess the quality, consistency and reliability of automatically extracted AI methodology metadata.
The project involved:
- benchmarking generated annotations against manually curated DOME annotations
- evaluating semantic similarity between LLM outputs and human expert annotations
- analyzing reporting quality across AI method disclosure categories
- assessing scalability of automated literature annotation pipelines
- studying hallucination avoidance and information extraction performance
Code
DOME Copilot Data Analysis can be found here.
Related Publication
Preprint available on bioRxiv.
Funding
This work was supported by ELIXIR, AI4EOSC, EVERSE and ELIXIR STEERS initiatives supporting trustworthy and reproducible artificial intelligence in life sciences.